

What is a web crawler? Web crawlers explained
If you have worked with digital marketing and SEO, you may have often heard words such as ‘web crawler’ and crawling. In this article, we introduce some basic concepts about web crawlers and crawling.
What is a Web crawler?
A Web crawler is a program that automatically collects information. This information can be text, images, and videos published on the Internet and stores it in a database. Also called “bot”, “spider”, “robot” etc.
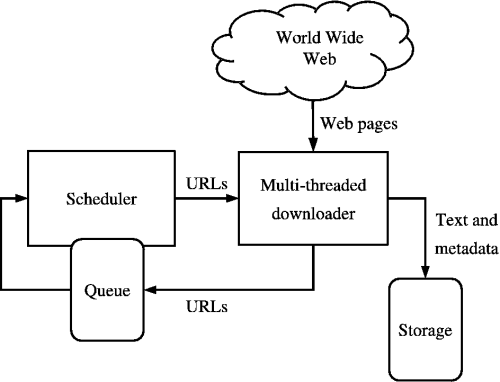
Web crawler types & functions
1. Search engine crawler
It is a crawler for traveling around the site. Among other things, it can also do things such as collecting characters and images in the site, and accumulating it as the original data for search. In fact, it is one of the best examples of crawlers.
The famous search engine crawlers are:
- Googlebot (Google)
- Bingbot (Microsoft)
- Yahoo Slurp (Yahoo)
- Baiduspider (Baidu)
- Yetibot (Naver)
2. Fixed point observation crawler
It is a crawler for traveling regularly only at a fixed page of a fixed site and acquiring new arrival information and update information of the site. For example, it is possible to analyze weekly price fluctuations and automatically create sales strategy data that summarizes prices, price fluctuations, and so on by acquiring price data for each product from multiple price sites.
3. SEO measures crawler
In SEO, crawlers are responsible for indexing pages to display pages in search results. So, which page the crawler is loading on your site is one of the guiding principles for improving your SEO efforts. In fact, there is a great free tool from Google called “Google Search Console”. You can use this tool for detailed information about crawler behavior.
Cautions when using a Web crawler
Business, sales, and marketing can be made effective by using web crawlers. However, there are points to be aware of when using a web crawler.
When extracting information from multiple pages, continuous access will load the Web server. In such cases, we can consider it to be a problem of the crawling side, or even as a DDoS attack (a load that overloads the server and disrupts service).
So it is important not to put too much load on the server, not to trigger unnecessary actions, and to be able to crawl the web site repeatedly at appropriate intervals.