

10 Important Algorithms in Machine Learning
The word “Big Data” became popular in 2017 and has become the most popular in the high-tech industry. Machine learning lets computers analyze past data and predict future data. It is now popular in many fields. In fact, even engineers who do not specialize in machine learning can now use it. This article introduces some of the most commonly used machine learning algorithms.
1. Random forest
Random forest is a machine learning technique that you can use for classification and regression. It is a technique that makes many decision trees and merges them together. Although random forest technique
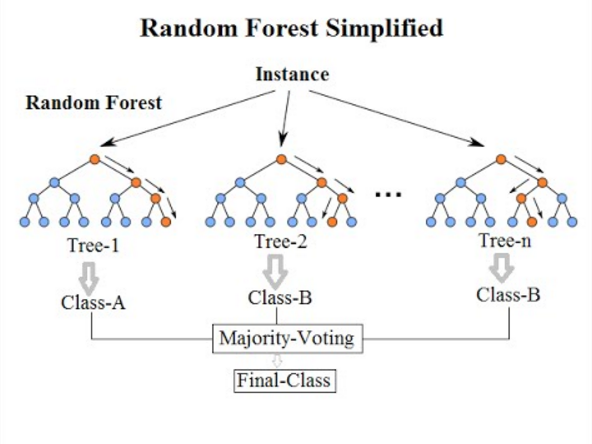
Let’s look at an example: There are training data: [X1, X2, X3, … X10]. As shown above, a random forest can use bagging (short for bootstrap aggregating) to divide the data set into three subsets and randomly select data from the subsets to create three decision trees I can do it. The final output determines the majority (for classification) or the mean (for regression).
2. Decision tree
Decision trees are a method of dividing and classifying groups by conditional branching. It divides the data into groups as similar as possible. I think that it is easier to understand if you look at the image below.
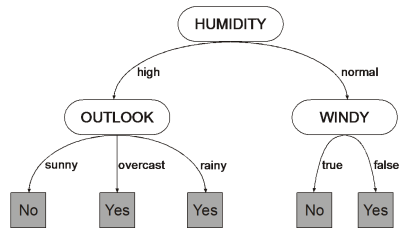
By repeating the conditional branch in this way, we expand the data more and more like a tree and divide it into the smallest solvable units.
They are one of the simplest machine learning algorithms.
3. Logistic regression
Logistic regression is a type of statistical regression model of variables that follow the Bernoulli distribution. If the probability P is between zero and one, (0 <P <1), it can not be satisfied by a normal linear model. If the domain is not within a certain level, the range will exceed the specified interval.
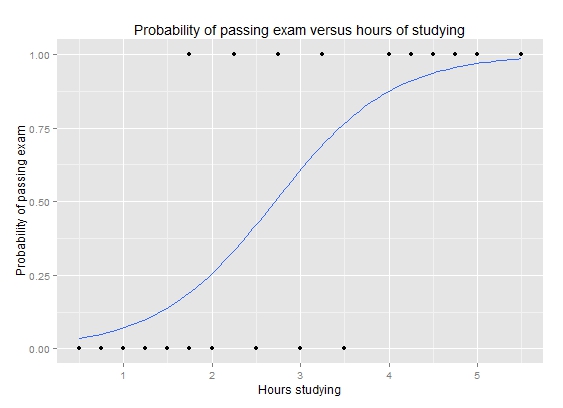
The following is a form of
4. Naive Bayesian classifier
A naive Bayesian classifier is a
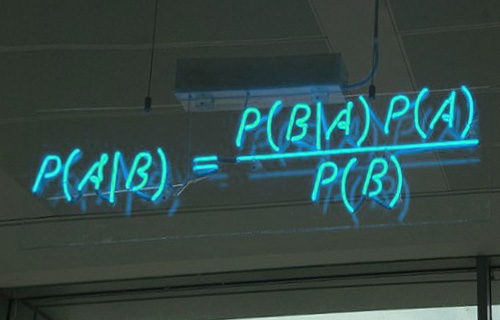
This image represents Bayesian theorem, where P (A | B) is the posterior probability, P (B | A) is the likelihood, P (A) is the prior probability of the classification class, and P (B) is the predictor variable. It is a prior probability. We use Naive Bayesian mainly for text classification, etc. Also, other common uses are detecting spam emails, emotion checks on text, and tagging of articles posted on the Web.
5. Support Vector Machine (SVM)
Support Vector Machine is a pattern recognition model using supervised learning. With this method, we can construct two classes of pattern classifiers using linear input elements.
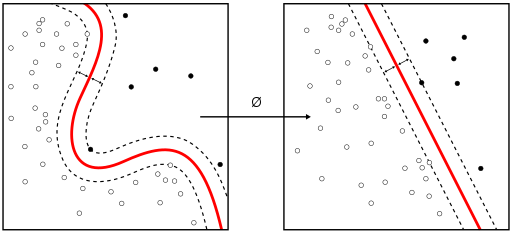
The problems that properly implemented SVMs solve include display advertisements, human splice site recognition, image-based gender detection, and large-scale image classification.
6. k-nearest neighbor
The k-nearest neighbor method is a classification method on the basis of the
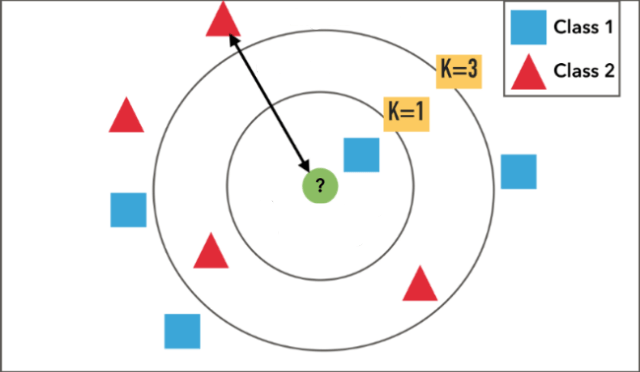
For example, in the case of the figure above, the flow of class determination is as follows.
- Plot the known data (training data) as red triangles and blue squares.
- Determine the number of K. K = 1 and so on.
- If we obtain a green circle as unknown data, we will acquire one from the near point.
- Estimate the class to which the one class belongs by the
majority . This time, we suppose that the unknown green circle belongs to Class 1.
*Please note that the result changes depending on the number of K. When K = 3, we judge the green circle as Class 2.
7. k-means
The k-means method is a clustering algorithm. Clustering groups data into similar classifications. k-means is one of the simplest methods of clustering
- Choose k samples to be the “nucleus” of the cluster.
- Measure the distance between all samples and k “nucleus”.
- Divide each sample into the same cluster as the nearest “nucleus”. (We divide all samples into k types at this point)
- Find the centroids of k clusters, and use them as new kernels. (Here, the position of the center of gravity is moving.)
- If the position of the center of gravity changes, the process returns to step 2. (Repeat until the center of gravity does not change)
- The center of gravity does not change and the process ends.

8. AdaBoost
AdaBoost is a machine learning model that attempts to create strong classifiers by combining weak classifiers that are slightly more accurate than random ones.
The flow of making is to first apply weak classifiers, increase the weight of those that have been misclassified, and then prioritize and classify those that have the weight. Then repeat it.
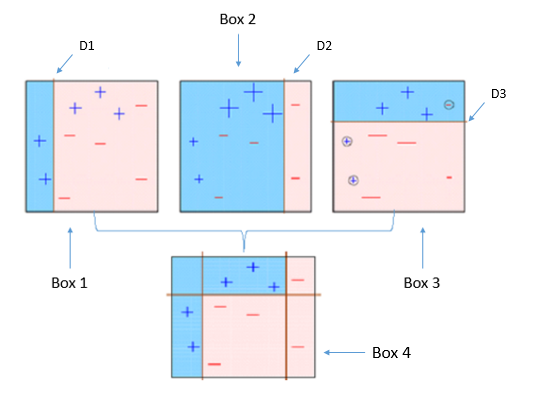
It is easy to understand if you refer to the figure above.
In the above figure, we first use a weak classifier at D1 to classify and increase the ‘+’ 1 and ‘-‘2 weights that are misclassified at D2.
Next, the three misclassified are considered with priority and classified. Here, at the same time as the weights are increased, the weights of others that are correctly classified are decreasing.
In addition, D3 increases the ‘-‘3 weight misclassified in D2 while decreasing the weight at the same time as others.
In this manner, we can make a strong classifier based on the weights of the repeated classifications.
9. Neural networks
A neural network is a combination of mathematically modeled neurons in the human nervous system.
This is a simplified model of neuron behavior. Artificial neural networks differ from biological brains in that data transmission methods are pre-defined in terms of layers, connections, and directions, and can not be transmitted differently.
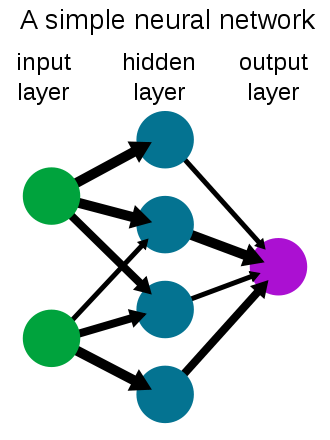
A neural network consists of a series of layers of neurons where all the neurons in one layer
10. Markov chain
A Markov chain is a set of random variables X1, X2, X3, … where the past and future states are independent, given the current state.
As a specific example of Markov chain, consider the following model (probability is quite appropriate but it helps to understand Markov chain).
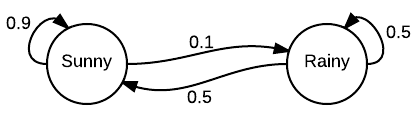
Such a diagram is called a state transition diagram. It shows the probability of different events happening after each other.
Summary
Engineers with machine learning skills are in high demands from companies. So naturally, they can have a big advantage, if they can learn these skills. A complete mathematical understanding of machine learning algorithms requires a lot of